Scimba basics I: approximation of the solution of a 2D Laplacian¶
In this first tutorial, we’ll walk you through the basic steps to approximate the solution of a 2D Laplacian Partial Differential Equation (PDE) with a Scimba Physics-Informed Neural Network (PINN).
We consider the equation:
on \((x,y) \in \Omega := [0, 1]\times[0, 1]\) with parameter \(\mu\in[1,2]\) subject to the Dirichlet condition:
on \(\partial\Omega\).
Scimba and torch setting¶
Scimba is based on torch for tensor arithmetic, auto-differentiation, neural networks definition and evaluation, etc.
At initialisation, Scimba sets:
torchdefault device to “cuda” if available, otherwise “cpu”,torchdefault floating point format totorch.double.
[1]:
import scimba_torch
import torch
torch.manual_seed(0)
print(f"torch device: {torch.get_default_device()}")
print(f"torch floating point format: {torch.get_default_dtype()}")
if torch.cuda.is_available():
print(f"cuda devices: {torch.cuda.device_count()}")
print(f"cuda current device: {torch.cuda.current_device()}")
print(f"cuda device name: {torch.cuda.get_device_name(0)}")
torch device: cuda:0
torch floating point format: torch.float64
cuda devices: 1
cuda current device: 0
cuda device name: Tesla V100-PCIE-16GB
This can be changed througth torch.set_default_device and torch.set_default_dtype functions. Notice that natural gradient descent algorithms used in Scimba require double precision arithmetic.
We demonstrate below how to change default device and floating point type.
By default, Scimba is silent; this can be changed as follows:
[2]:
print("scimba is verbose: ", scimba_torch.get_verbosity())
scimba_torch.set_verbosity(True)
print("scimba is verbose: ", scimba_torch.get_verbosity())
scimba is verbose: False
/////////////// Scimba 1.3.3 ////////////////
torch device: cuda:0
torch floating point format: torch.float64
cuda devices: 1
cuda current device: 0
cuda device name: Tesla V100-PCIE-16GB
scimba is verbose: True
Defining the geometric domain \(\Omega \subset \mathbb{R}^2\)¶
In Scimba, in a \(d\)-dimensional ambiant space,
\(d\)-dimensional geometric domains are objects of
class VolumetricDomain, and\(d-1\)-dimensional geometric domains are objects of
class SurfacicDomain.
Most common types of domains (carthesian products of intervals, disks, …) are implemented in scimba_torch.domain.meshless_domain.domainND (with N\(=1,2\) ou \(3\)).
Here, we define \(\Omega := [0, 1]\times[0, 1]\) with:
[3]:
from scimba_torch.domain.meshless_domain.domain_2d import Square2D
domain_x = Square2D([(0.0, 1), (0.0, 1)], is_main_domain=True)
The keyword argument is_main_domain indicates whether the created object is a main domain or is a subdomain of a main domain; Scimba allows to create complex geometries by combining holes and subdomains.
Samplers on \(\Omega\)¶
The next step is to define samplers for geometric and parameter’s domains. The module scimba_torch.integration provides uniform samplers for physical and parameter’s domains.
[4]:
from scimba_torch.integration.monte_carlo import DomainSampler, TensorizedSampler
from scimba_torch.integration.monte_carlo_parameters import UniformParametricSampler
domain_mu = [(1.0, 2.0)]
sampler = TensorizedSampler(
[DomainSampler(domain_x), UniformParametricSampler(domain_mu)]
)
Scimba tensors and functions of such¶
Batches of \(n\) points in physical domains and batches of \(n\) parameter’s values are represented in Scimba with elements of class LabelTensor, which are \((n,d)\)-shaped tensors with additional informations.
Let us define the right-hand-sides of our target equation as functions of LabelTensor:
[5]:
from scimba_torch.utils.scimba_tensors import LabelTensor
def f_rhs(xs: LabelTensor, ms: LabelTensor) -> torch.Tensor:
x, y = xs.get_components()
mu = ms.get_components()
pi = torch.pi
return 2 * (2.0 * mu * pi) ** 2 * torch.sin(2.0 * pi * x) * torch.sin(2.0 * pi * y)
def f_bc(xs: LabelTensor, ms: LabelTensor) -> torch.Tensor:
x, _ = xs.get_components()
return x * 0.0
def exact_sol(xs: LabelTensor, ms: LabelTensor) -> torch.Tensor:
x, y = xs.get_components()
mu = ms.get_components()
pi = torch.pi
return mu * torch.sin(2.0 * pi * x) * torch.sin(2.0 * pi * y)
Approximation space¶
In Scimba, the solution of a PDE is approximated by an element \(v\) of a set of parameterized functions called approximation space.
Here we wish to approximate the solution with a Multi-Layer Perceptron with 3 inputs (\(x,y\) and \(\mu\)), 1 output (\(u(x,y,\mu)\)) and an intermediate layer of \(64\) neurons:
[6]:
from scimba_torch.approximation_space.nn_space import NNxSpace
from scimba_torch.neural_nets.coordinates_based_nets.mlp import GenericMLP
space = NNxSpace(
1, # the output dimension
1, # the parameter's space dimension
GenericMLP, # the type of neural network
domain_x, # the geometric domain
sampler, # the sampler
layer_sizes=[64], # the size of intermediate layers
)
Physical model¶
Several PDEs are implemented in Scimba and ready-to-use; here we use the 2D Laplacian in strong form with Dirichlet boundary condition:
[7]:
from scimba_torch.physical_models.elliptic_pde.laplacians import (
Laplacian2DDirichletStrongForm,
)
pde = Laplacian2DDirichletStrongForm(space, f=f_rhs, g=f_bc)
One can also taylor its own model as described in this tutorial.
Scimba PINN¶
Scimba implements PINNs and preconditioned PINNS; here we wish to use a Energy Natural Gradient preconditioner:
[8]:
from scimba_torch.numerical_solvers.elliptic_pde.pinns import (
NaturalGradientPinnsElliptic,
)
pinn = NaturalGradientPinnsElliptic(pde, bc_type="weak")
pinn.solve(epochs=200, n_collocation=1000, n_bc_collocation=1000)
print(f"Training time: {pinn.training_time:.2f} seconds")
print(f"Best Loss : {pinn.best_loss:.2e}")
Training: 100%|||||||||||||||||| 200/200[00:23<00:00] , loss: 9.5e+03 -> 2.5e-03
Training time: 41.64 seconds
Best Loss : 2.47e-03
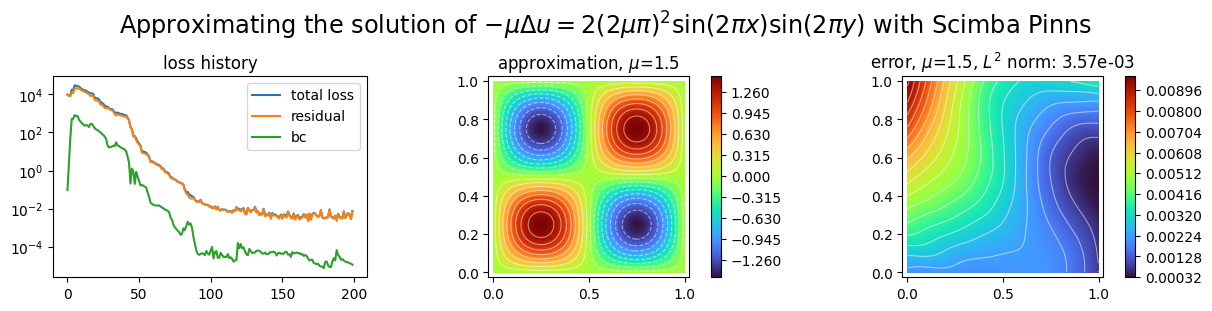
Plotting the approximation¶
[9]:
import matplotlib.pyplot as plt
from scimba_torch.plots.plots_nd import plot_abstract_approx_spaces
plot_abstract_approx_spaces(
pinn.space, # the approximation space
domain_x, # the spatial domain
domain_mu, # the parameter's domain
loss=pinn.losses, # optional plot of the loss: the losses
error=exact_sol, # optional plot of the approximation error: the exact solution
draw_contours=True, # plotting isolevel lines
n_drawn_contours=20, # number of isolevel lines,
title=(
"Approximating the solution of "
r"$- \mu\Delta u = 2(2\mu\pi)^2 \sin(2\pi x) \sin(2\pi y)$"
" with Scimba Pinns"
),
)
plt.show()
Scimba_jax uses device: [CudaDevice(id=0)]
Scimba_jax uses dtype: <class 'jax.numpy.float64'>
Setting floating point arithmetic precision¶
Use regular torch instruction for this:
[10]:
torch.set_default_dtype(torch.float32)
scimba_torch.print_torch_setting()
torch device: cuda:0
torch floating point format: torch.float32
cuda devices: 1
cuda current device: 0
cuda device name: Tesla V100-PCIE-16GB
Now re-define the PINN and solve it.
[11]:
def solve_with_pinn(epochs=200, layer_sizes=[64], n_collocation=1000, n_bc_collocation=1000):
domain_x = Square2D([(0.0, 1), (0.0, 1)], is_main_domain=True)
domain_mu = [(1.0, 2.0)]
sampler = TensorizedSampler(
[DomainSampler(domain_x), UniformParametricSampler(domain_mu)]
)
space = NNxSpace(1, 1, GenericMLP, domain_x, sampler, layer_sizes=layer_sizes)
pde = Laplacian2DDirichletStrongForm(space, f=f_rhs, g=f_bc)
pinn = NaturalGradientPinnsElliptic(pde, bc_type="weak")
pinn.solve(epochs=epochs, n_collocation=n_collocation, n_bc_collocation=n_bc_collocation)
print(f"Training time: {pinn.training_time:.2f} seconds")
print(f"Best Loss : {pinn.best_loss:.2e}")
solve_with_pinn()
Training: 100%|||||||||||||||||| 200/200[00:14<00:00] , loss: 9.5e+03 -> 6.8e+03
Training time: 14.55 seconds
Best Loss : 6.78e+03
Natural gradient preconditionning is not well suited for simple precision arithmetic.
Setting device¶
[12]:
torch.set_default_device("cpu")
torch.set_default_dtype(torch.float64)
scimba_torch.print_torch_setting()
torch device: cpu
torch floating point format: torch.float64
cuda devices: 1
cuda current device: 0
cuda device name: Tesla V100-PCIE-16GB
Now re-define the PINN and solve it.
[13]:
solve_with_pinn(epochs=10)
Training: 100%|||||||||||||||||||| 10/10[01:23<00:00] , loss: 8.6e+03 -> 8.6e+03
Training time: 83.59 seconds
Best Loss : 8.62e+03